
- Details
- Category: AI for Patents
In the rapidly evolving field of AI, Kama Thuo, PLLC offers comprehensive legal services to help clients navigate the intricate landscape of AI development and application. This includes strategic counsel on patenting AI technologies, managing AI risks, and ensuring compliance with privacy and other legal requirements. Kama Thuo focuses on fostering innovation while protecting intellectual assets by helping clients leverage AI technologies to gain competitive advantages and achieve long-term success.
Navigate the below articles to learn more about:
- Machine Learning in Patent Analysis.
- Best AI Foundation Models for Patent Analysis.
- How to Train AI Models for Patent Analysis.
See also patent analysis preferred non-lawyer vendors and tools:
- AI Automation Vendor: Rfwel Engr AI Group
- Patent Analysis AI Tool: patanal.ai
- Patent Analytics Vendor: Patent Analytics, Inc
- Wireless Technology Consultants: Rfwel Engr WDI Research
- Details
- Category: AI for Patents
Patent professionals spend hundreds of hours on prior art searches and freedom-to-operate analyses. KTH Law's PatentWorkflow AI is a free, open-source web application that generates production-ready n8n workflow configurations - turning complex, multi-step patent analysis into automated pipelines powered by large language models.
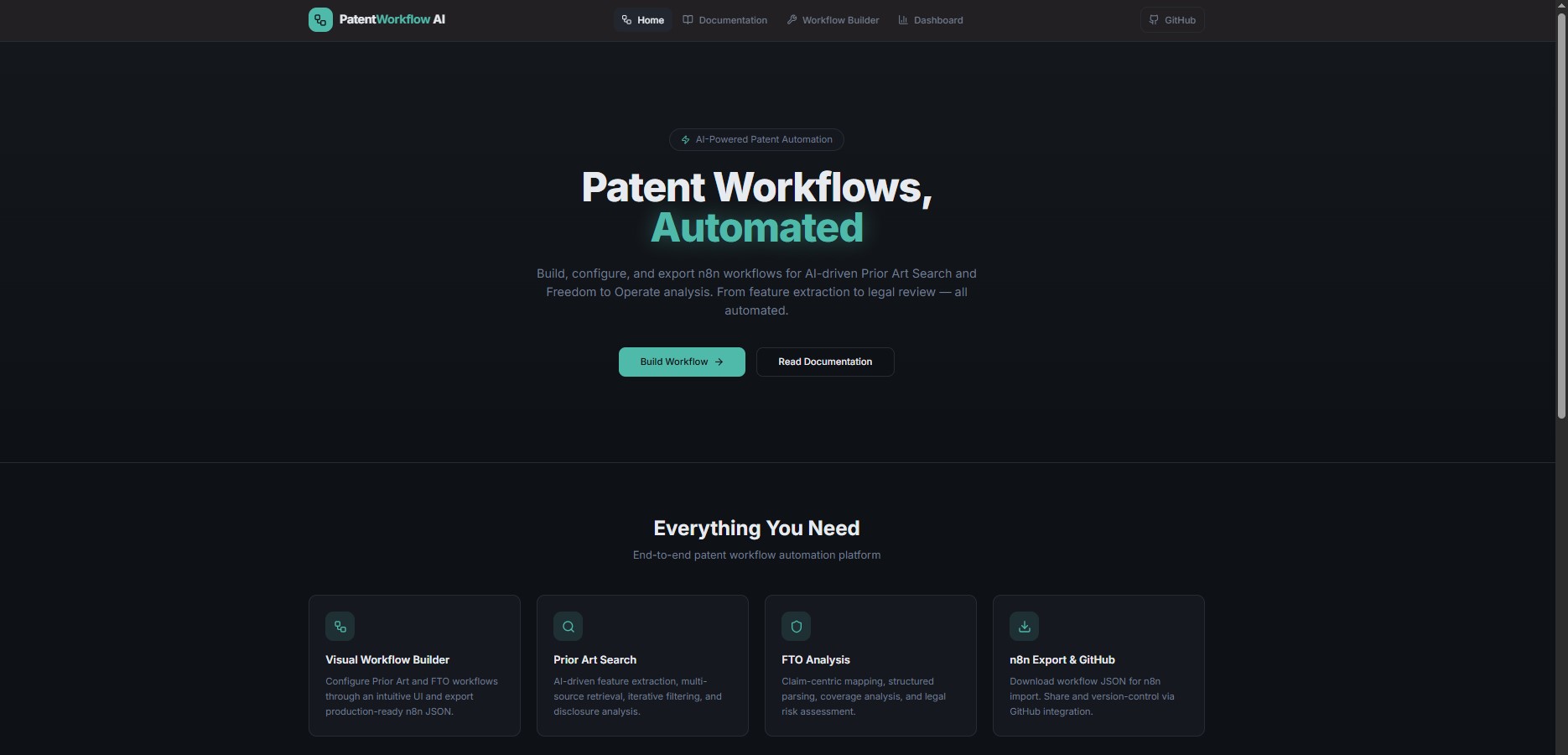
PatentFlow AI landing page: configure Prior Art and FTO workflows
| Prior Art Search | FTO Analysis |
|
The Prior Art workflow automates the discovery |
The Freedom to Operate workflow determines whether a product may infringe existing patent claims. Unlike prior art search, FTO is claimcentric - it maps product features directly to structured claim elements and quantifies infringement risk. |
| 1. Feature Extraction - structured technical features from specs | 1. Feature-to-Claim Mapping - functional similarity analysis |
| 2. Query & Retrieval - multi-source patent database search | 2. Claim Parsing - structured decomposition of limitations |
| 3. Iterative Filtering - semantic similarity and CPC/IPC overlap | 3. Coverage Analysis - full match, partial overlap, or no match |
| 4. Disclosure Analysis - feature-to-patent evidence mapping | 4. Legal Review - risk assessment and design around options |
| 5. Human Review - attorney validation and strategy |
The Workflow Builder
The visual Workflow Builder provides an intuitive interface for configuring patent analysis parameters. Users select the workflow type, enter product details, choose an AI model (GPT-5/GPT-5.2, Claude 4.6, etc.), pick patent data sources, and generate production-ready n8n JSON - downloadable with a single click.
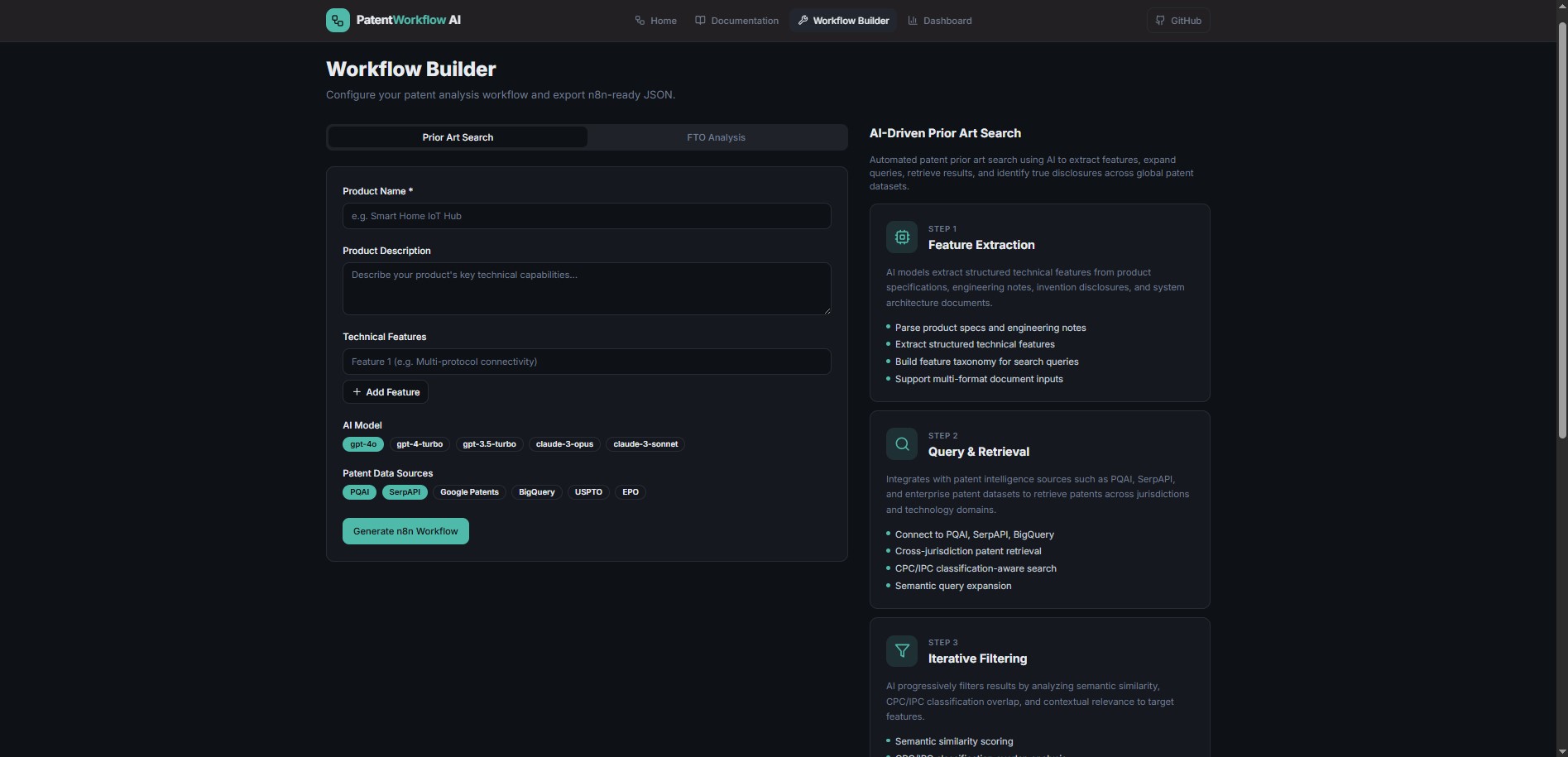
Workflow Builder: configure parameters and generate n8n JSON for import
Getting Started
PatentFlow AI is completely free and open source. No account required - visit the web app, configure your workflow, and download the n8n JSON.
- Visit patent-n8n-flows.lovable.app
- Choose Prior Art Search or FTO Analysis
- Enter product name and technical features
- Select AI model and patent data sources
- Generate and download n8n workflow JSON
- Import into n8n and configure API
credentials - Activate/publish
You can also fork the project from github:
ℹ AVAILABLE ON GITHUB Fork it. Extend it. Contribute workflows: github.com/kthlaw/patent-n8n-flows
About the Author and Firm
This analysis is provided by Kama Thuo, PLLC, an engineering & technology law firm focused on patents, AI, and wireless telecom law. Brian Kibet is a multidisciplinary professional with expertise in wireless engineering, paralegal practice, and software development. With a strong background in AI and automation, he designs intelligent workflows for intellectual property processes, with a focus on patent-related work, bridging the gap between technical innovation and legal strategy.
Whether you are an inventor seeking to license your technology or a company navigating an IP dispute, our firm has the technical and legal expertise to protect your interests. Reach out to us to see how we can assist you at www.kthlaw.com/patents, or explore our AI-powered legal services at https://www.kthlaw.com/ai.
- Details
- Category: AI for Patents
Freedom to Operate (FTO) analysis is a critical step in the product commercialization process. While prior art searches focus on novelty and patentability, FTO focuses on infringement risk-determining whether a product or system may fall within the scope of existing patent claims.
Like the AI-driven prior art workflow, this approach extends similar pipeline to focus on claim-level analysis, enabling organizations to assess legal exposure and make informed go-to-market decisions.
Prior Art Search → Feature-centric (What has been disclosed?): Focuses on identifying whether similar technical features, concepts, or implementations have already been described in existing patents or literature, primarily to assess novelty and patentability.
FTO Analysis → Claim-centric (What is legally protected?): Focuses on interpreting active patent claims to determine the legal scope of protection and whether a product or system may infringe, supporting risk assessment and commercialization decisions.
Business Scenario: Smart Home IoT Hub
Consider a smart home IoT hub with features such as multi-protocol connectivity, edge-AI automation, and voice integration, an FTO flow will be as follows.
After the patents have been analyzed for features, they can be pipelined for FTO search. Additionally, new other patents can be found by using the AI n8n workflow, then the following can be done:
Step 1: Feature-to-Claim Mapping
AI based workflow can analyze the product or system at a technical level and systematically align its core features with corresponding elements found in patent claims. This process goes beyond simple keyword matching by interpreting functional similarities, technical behaviors, and architectural patterns, enabling a more accurate linkage between what the product does and what the patent legally protects.
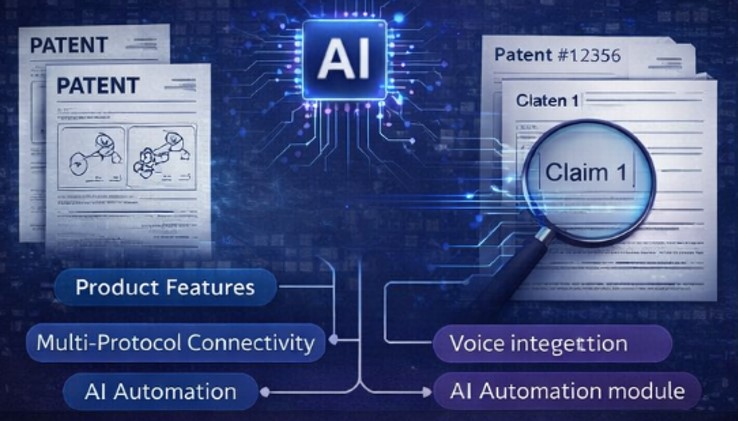
Illustration of product features mapping to patent claims
Step 2: Claim Parsing and Structuring
Patent claims are processed and decomposed into structured, machine-readable elements such as individual limitations, dependencies, and scope qualifiers. By breaking down complex legal language into organized components, AI enables precise comparison and downstream analysis, making it easier to understand how each part of a claim contributes to the overall protection.

Illustration of AI parsing of patent claims
Step 3: Claim Coverage Analysis
AI evaluates the degree to which product features map to the structured claim elements, determining whether there is a full match, partial overlap, or no correspondence. This analysis helps quantify potential infringement risk by assessing how comprehensively the product falls within the scope of one or more claims, while also highlighting gaps or distinctions that may reduce exposure.
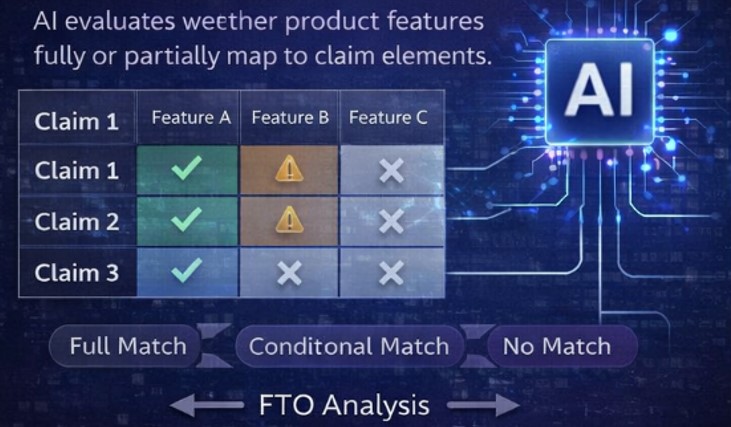
Claim analysis illustration
Step 4: Human-in-the-Loop Legal Review
Patent attorneys and technical experts review the AI-generated mappings and analysis to validate accuracy, interpret claim scope, and assess legal risk in context. This step incorporates professional judgment to refine conclusions, identify design-around opportunities or licensing needs, and ensure that final decisions are grounded in both technical insight and legal expertise.

Human review of AI results
n8n Sample Workflow
Advantages of an AI-based workflow:
- Faster identification of infringement risks
AI accelerates the analysis of large patent portfolios by quickly mapping product features to claim elements, enabling teams to identify potential infringement risks much earlier in the product development lifecycle and reduce delays in decision-making. - Scalable and consistent claim analysis
The workflow allows organizations to analyze thousands of patents systematically and consistently, overcoming the limitations of manual review while ensuring that claim interpretation and mapping follow a structured and repeatable approach. - Improved collaboration between legal and engineering teams
By translating complex patent claims into structured, feature-level insights, the workflow creates a shared understanding between legal and technical teams, facilitating more effective discussions, faster validation, and better-informed strategic decisions.
Conclusion
By extending AI workflows from feature-based discovery to claim-based analysis, organizations can ensure safer commercialization decisions.
About the Author and Firm
This analysis is provided by Kama Thuo, PLLC, an engineering & technology law firm focused on patents, AI, and wireless telecom law. Brian Kibet is a multidisciplinary professional with expertise in wireless engineering, paralegal practice, and software development. With a strong background in AI and automation, he designs intelligent workflows for intellectual property processes, with a focus on patent-related work, bridging the gap between technical innovation and legal strategy.
Whether you are an inventor seeking to license your technology or a company navigating an IP dispute, our firm has the technical and legal expertise to protect your interests. Reach out to us to see how we can assist you at www.kthlaw.com/patents, or explore our AI-powered legal services at https://www.kthlaw.com/ai.
- Details
- Category: AI for Patents
Artificial intelligence has fundamentally reshaped how prior art and patentability searches are conducted. What was once a labor-intensive, keyword-heavy process is now increasingly driven by semantic understanding, feature extraction, and multimodal analysis. The question is no longer whether to use AI in patent search workflows - but how to use it effectively.
This article explores that question from two angles: the perspective of patent law firms navigating the limitations of existing AI tools, and a practical, do-it-yourself (DIY) approach for patent professionals and innovators using accessible AI technologies.
The Evolving Nature of Prior Art Search
Traditional prior art searches relied heavily on Boolean queries, classification codes (e.g., CPC), and manual review of patent documents. While these methods remain relevant, they are inherently limited by language dependency - missing relevant disclosures that describe similar inventions using different terminology.
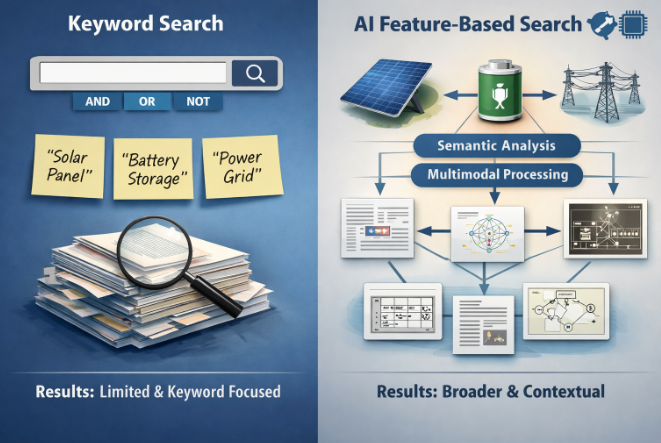
AI-driven search changes the paradigm. Instead of asking, “What keywords match this invention?”, the system instead focuses on identifying the core technical features of an invention, mapping those features across existing disclosures, and uncovering functional or structural equivalence regardless of how something is described. Modern AI systems leverage natural language processing, embeddings, and increasingly computer vision to uncover deeper relationships across patent literature.
keyword search vs AI feature-based search
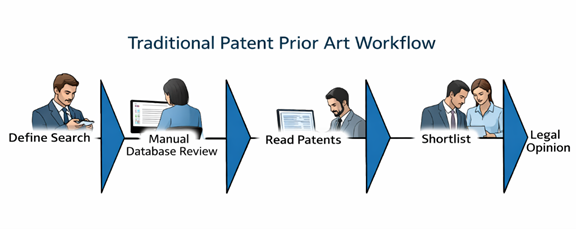
Limitations of Existing AI Tools from a Patent Law Firm Perspective
Despite rapid advancements, AI tools for patent search still present several limitations that law firms must navigate carefully. One of the most significant challenges is the lack of true legal reasoning. While AI tools are highly effective at retrieving and summarizing technical content, they do not reliably interpret legal standards such as novelty and non-obviousness. These determinations require understanding claim scope, applying legal doctrines, and evaluating how prior art would be interpreted by a patent examiner or court-tasks that still depend heavily on human expertise.
Another ongoing concern is the issue of hallucinations and overconfidence. Even advanced AI systems can generate fabricated citations or misinterpret disclosures, often presenting their outputs with unwarranted certainty. In a legal environment where accuracy and traceability are critical, this introduces real risk. Law firms must therefore implement strong validation processes to ensure that all AI-assisted findings are grounded in actual source material.
Data coverage is also a persistent limitation. Many AI tools rely on incomplete or proprietary datasets, which may exclude important non-patent literature, foreign-language filings, or recently published applications. This fragmentation means that no single tool can be relied upon for comprehensive global searches, forcing practitioners to combine multiple sources.
Additionally, while multimodal AI is improving, most tools still struggle to extract meaningful technical insights from patent drawings and figures. In many fields-especially mechanical, electrical, and design-heavy inventions-figures carry critical disclosure, and the inability to effectively interpret them creates blind spots in the search process.
Finally, there is the practical issue of workflow integration. Many AI tools operate as standalone platforms that do not integrate smoothly with internal law firm systems such as document management, docketing, or review pipelines. This often results in fragmented workflows rather than a seamless, end-to-end AI-assisted process.
Example law firm workflow showing AI + human-in-the-loop validation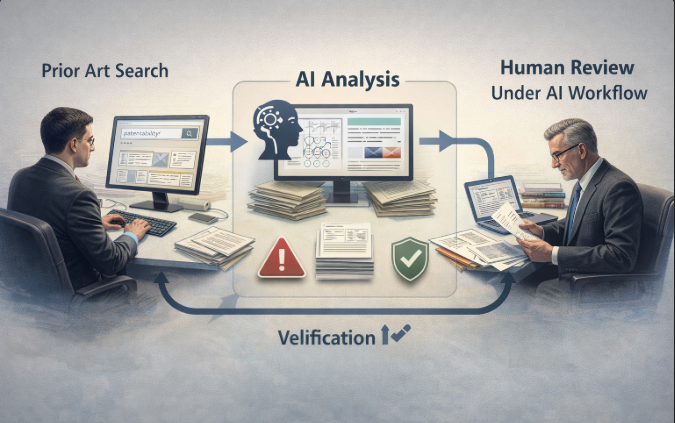
A DIY Approach: What Patent Professionals Can Do with Existing AI Tools
For individual practitioners, patent agents, and even business teams, the rise of accessible AI tools has opened up powerful new possibilities for conducting effective prior art searches without relying solely on enterprise platforms.
A strong starting point is to deconstruct the invention into its core technical features. Instead of working with a broad narrative description, AI can be used to extract structured elements such as components, functional relationships, and distinctions between essential and optional features. This structured representation becomes the backbone of a more intelligent search strategy.
From there, AI can be used to generate a wide range of semantic search queries. Rather than relying on a fixed set of keywords, users can prompt AI to produce alternative descriptions, synonyms, and functionally equivalent phrases. This expands the search space significantly and helps uncover prior art that would otherwise be missed using traditional keyword methods.
These AI-generated queries can then be combined with public patent databases such as Google Patents, Espacenet, and The Lens. Once relevant documents are identified, they can be fed back into AI systems for summarization, relevance ranking, and deeper analysis. This iterative loop-search, analyze, refine-allows for progressively better results.
Another powerful use of AI is in feature mapping. By comparing the extracted features of an invention against those found in prior art, AI can help generate early-stage claim charts that highlight overlaps and gaps. While not legally definitive, this provides a strong foundation for assessing novelty and identifying potential risks.
Example of AI-generated feature mapping table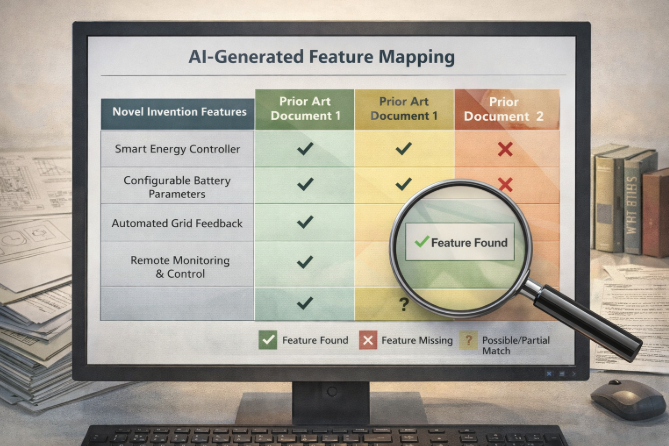
Multimodal capabilities further enhance this process. By uploading patent figures or technical diagrams, users can prompt AI to interpret structural elements and compare them to the invention’s features. This is particularly valuable in technical domains where visual representations carry as much weight as written descriptions.
At the core of this DIY approach is the principle of maintaining a human-in-the-loop workflow. AI should be used for discovery, expansion, and initial analysis, while human expertise remains essential for validation, interpretation, and legal judgment. The most effective workflows are iterative, with continuous refinement of both the search strategy and the evaluation of results.
Best Practices
To effectively utilize AI in prior art and patentability searches, practitioners should adopt a mindset that prioritizes features over keywords, always validates AI outputs against original sources, and leverages multiple tools to reduce blind spots. Search should be treated as an iterative process rather than a one-time task, and documentation should be maintained throughout to ensure defensibility and transparency.
The Road Ahead
AI is rapidly evolving toward deeper multimodal understanding, improved feature mapping, and early forms of automated claim analysis. However, it has not yet reached the point of replacing professional judgment. The practitioners who will benefit most are those who understand both the strengths and the limitations of AI-using it to augment their capabilities rather than replace them.
Conclusion
AI has transformed prior art and patentability search from a rigid, keyword-driven process into a dynamic, intelligence-driven workflow. For law firms, the challenge lies in integrating these tools responsibly within established legal practices. For individual practitioners and innovators, the opportunity lies in leveraging accessible AI tools to perform sophisticated searches that were previously out of reach.

Ultimately, the most effective approach is not AI alone, but a thoughtful combination of AI capabilities, structured workflows, and expert human judgment.
About the Author and Firm
This analysis is provided by Kama Thuo, PLLC, an engineering & technology law firm focused on patents, AI, and wireless telecom law. Colletar Nthambi is a versatile professional specializing in wireless engineering and paralegal practice. With strong technical expertise in telecommunications, she supports engineering and IP-related legal work, bridging the gap between wireless innovation and legal strategy.
Whether you are an inventor seeking to license your technology or a company navigating an IP dispute, our firm has the technical and legal expertise to protect your interests. Contact us to learn how we can help you at www.kthlaw.com/patents or explore our AI-powered legal services at https://www.kthlaw.com/ai.
- Details
- Category: AI for Patents
 |
Patent prior art search is an essential step in the innovation lifecycle. Before investing heavily in product development or filing a patent application, companies ought to understand whether similar inventions or technical solutions have already been disclosed in earlier patents. Traditionally, this process has been manual, time‑consuming, and heavily dependent on the experience of patent attorneys and professional search firms. This article explores how an AI‑driven workflow built using n8n can be use to perform structured and scalable patent prior art searches. The focus is not only on claim interpretation (when the prior art search is against existing or prospective new claims), but more importantly on identifying technical features disclosed across patent specifications and drawings. |
ℹ Why Features Matter More Than Keywords Traditional prior art searches rely heavily on keyword matching, which often misses relevant patents that describe the same concept differently. In an AI-driven workflow, the focus shifts to technical feature extraction and mapping - identifying what the invention actually does, not just how it is described. This allows the system to uncover semantically similar disclosures across patents, even when different terminology is used, significantly improving search depth and accuracy.
Business Scenario: Smart Home IoT Hub Innovation
Consider a smart home technology company developing a next‑generation IoT hub designed to orchestrate multiple connected devices. The hub includes features such as multi‑protocol wireless connectivity (Wi‑Fi, Zigbee, Bluetooth), edge‑AI automation rules, voice assistant integration, device prioritization, and secure Over‑the‑Air firmware updates.
Companies can conduct prior art searches either by leveraging internal AI-powered patent search tools (such as PQAI, Perplexity or other similar platforms) or by engaging an external law firm or specialized patent search provider. Modern AI tools enhance this process by extracting technical features, expanding search queries semantically, and identifying relevant disclosures across large patent datasets more efficiently than traditional keyword-based methods.
The objective is to determine whether similar technical features have already been disclosed in earlier patents, thereby enabling organizations to assess patentability risk, refine their innovation and filing strategy, and uncover potential design-around opportunities.

AI‑Driven Prior Art Search Workflow Using n8n
Step 1: Feature Extraction
AI models extract structured technical features from product specifications, engineering notes, invention disclosures, and system architecture documents. These structured features form the foundation of large‑scale patent search queries.
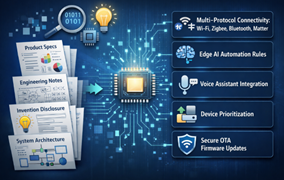
Illustration of feature extraction from product document using AI
Step 2: Query and Retrieval
The n8n workflow integrates with patent intelligence sources such as PQAI, SerpAPI, and enterprise patent datasets stored in BigQuery. The workflow retrieves patents across jurisdictions, classifications, and technology domains to ensure comprehensive coverage.

Various patent data sources can be leveraged to retrieve documents that align with the defined feature filters.
Step 3: Iterative Filtering
AI progressively filters results by analyzing semantic similarity, CPC/IPC classification overlap, and contextual relevance to target features. This iterative loop reduces noise while maintaining discovery breadth.
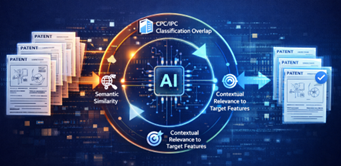
Patent results are filtered to generate a high-quality, relevant shortlist for further analysis
Step 4: Feature Disclosure Analysis
Instead of focusing purely on patent/claim language, AI evaluates whether patents disclose similar technical features, system behaviours, or architectural patterns within specifications, embodiments, and diagrams. Evidence snippets are extracted and scored for relevance.

AI evaluates patent documents by mapping technical features to disclosed elements, including both textual and visual
Step 5: Human‑in‑the‑Loop Legal and Technical Review
Patent attorneys and engineering teams review AI‑generated shortlists, validate feature mappings, interpret disclosure depth, and develop patent filing or innovation strategy recommendations.
ℹ AI + Human = Stronger Patent Strategy While AI speeds up patent discovery and analysis, it does not replace expert judgment. The best workflows combine AI-driven filtering with review by patent attorneys and engineers, ensuring results are both relevant and legally meaningful for stronger patent decisions.

Patent attorneys review and validate AI-generated results.
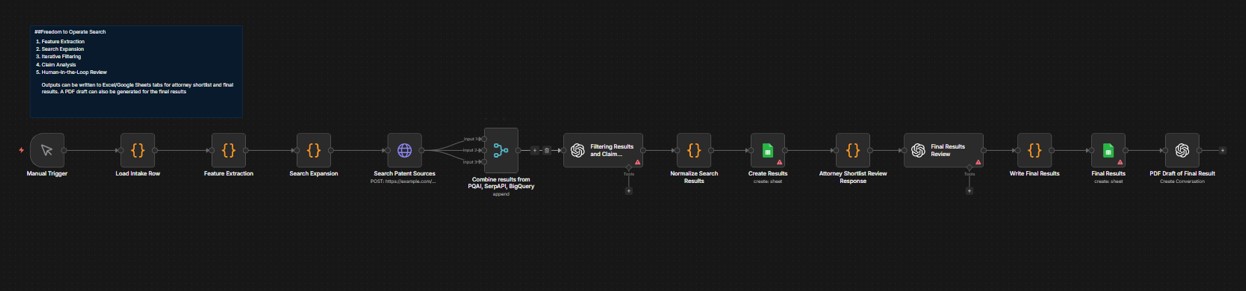
n8n Sample Workflow
This n8n workflow automates prior art search using AI. It extracts key features from inputs, expands search queries, and retrieves results from multiple patent sources. An iterative filtering step refines results based on semantic similarity and relevance, followed by feature-level analysis to identify true disclosures.
Results are structured into sheets for attorney review and final validation, enabling faster, more accurate decisions on patentability, strategy, and design-around opportunities.

sample n8n workflow for prior art search
Benefits of the Automated Prior Art Workflow
• Faster patentability risk assessment
• Deeper insight into disclosed technical solutions
• Scalable analysis across global patent datasets
• Stronger collaboration between legal and engineering teams
• Better innovation and R&D investment decisions
Conclusion
AI‑driven automation enables organizations to move from manual document review toward structured, evidence‑driven prior art discovery. By combining broad AI search with expert human judgment, companies can converge more quickly on meaningful prior disclosures and build stronger patent strategies in competitive technology markets.
About the Author and Firm
This analysis is provided by Kama Thuo, PLLC, an engineering & technology law firm focused on patents, AI, and wireless telecom law. Brian Kibet is a multidisciplinary professional combining expertise in wireless engineering, paralegal practice, and software development. With a background in AI and automation, he specializes in designing intelligent workflows for intellectual property processes, particularly in patent-related work. His focus is on leveraging AI to improve the speed, accuracy, and scalability of patent and trademark research, bridging the gap between technical innovation and legal strategy.
Whether you are an inventor seeking to license your technology or a company navigating an IP dispute, our firm has the technical and legal expertise to protect your interests. Reach out to us to see how we can assist you at www.kthlaw.com/patents, or explore our AI-powered legal services at https://www.kthlaw.com/ai.